What Is the Data Model?
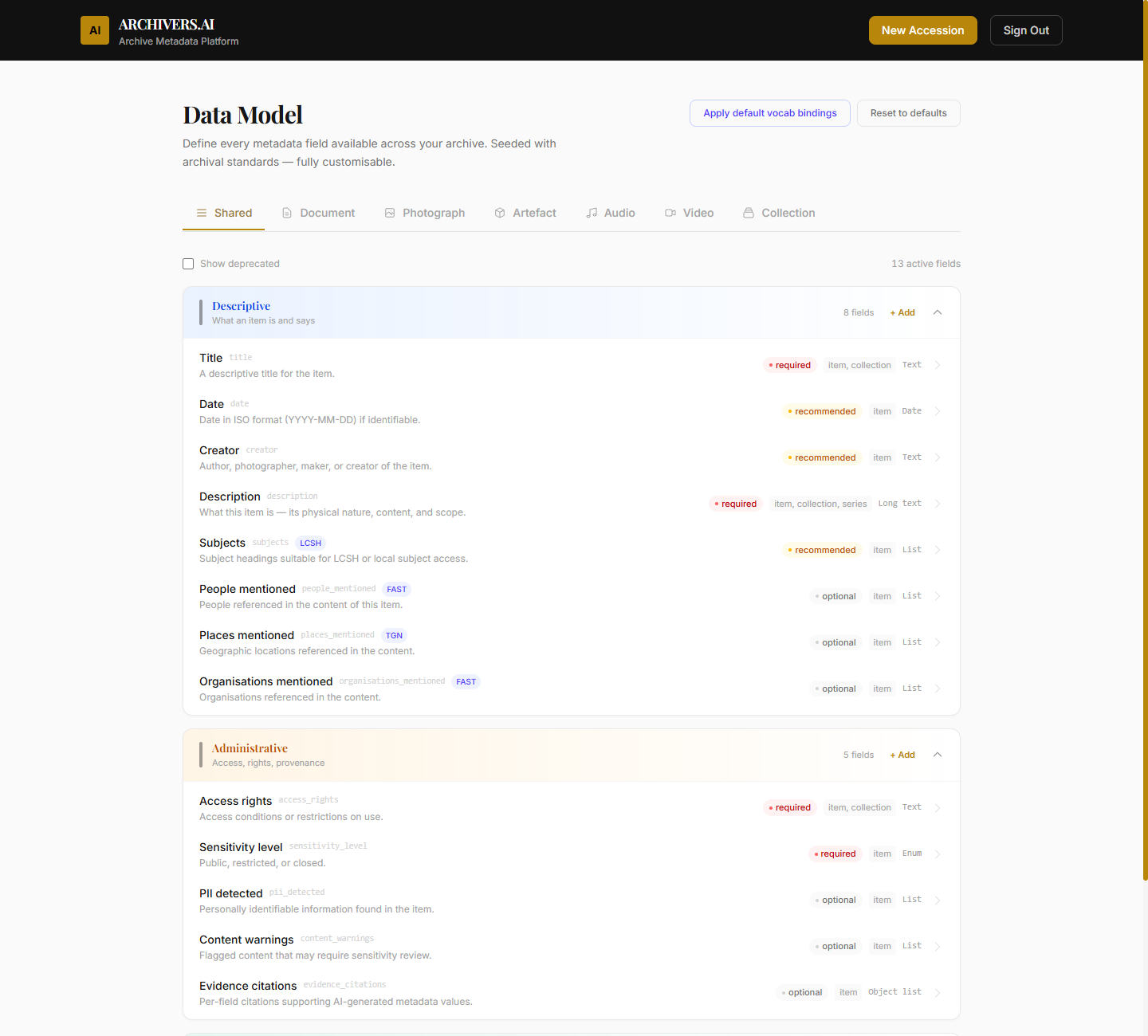
The Data Model defines every metadata field that exists in your archive — what shows up on documents, photographs, artefacts, audio items, video items, and at the collection level. It's seeded with archival-standards defaults (ISAD(G), DACS, Dublin Core, Spectrum) and fully customisable.
Find it at Settings → Data Model.
Why it matters
- The wizard surfaces these fields — when you create an accession, the Custom Fields step asks about each field your model has defined.
- The item review screen renders these fields — what you see when you expand a row on the Items tab.
- The AI populates these fields — what the model extracts is shaped by which fields are active and what they expect.
- Exports map from these fields — every format's mapping starts here.
Change the Data Model and every part of the platform that touches metadata updates accordingly.
How it's organised
The Data Model is split by category:
- Shared — fields that appear on every category (Title, Date, Creator, Description, Subjects, …)
- Document — bibliographic fields (publisher, language, page count, …)
- Photograph — image-specific fields (caption, photographer, technique, …)
- Artefact — conservation-style fields (materials, dimensions, condition, …)
- Audio — audio-specific fields (runtime, format, sample rate, transcript, …)
- Video — video-specific fields (runtime, resolution, codec, transcript, …)
- Collection — fond / sub-fond / series level fields (scope and content, biographical history, …)
Within each category, fields are grouped:
- Descriptive — what the item is
- Administrative — access, rights, provenance, sensitivity
- Conservation — condition, materials, environment (object-focused categories)
- Technical — format, dimensions, technical metadata
- Custom — your organisation's additions
The default schema
The defaults are derived from archival standards. A few examples:
Documents — Descriptive:
- Title (required, item / collection scope, Text)
- Date (recommended, item scope, Date)
- Creator (recommended, item scope, Text)
- Description (required, item / collection / series scope, Long text)
- Subjects (recommended, item scope, List, bound to LCSH)
- People mentioned (optional, item scope, List, bound to FAST)
- Places mentioned (optional, item scope, List, bound to TGN)
- Organisations mentioned (optional, item scope, List, bound to FAST)
Documents — Administrative:
- Access rights (required, item / collection scope, Text)
- Sensitivity level (required, item scope, Enum: Public / Restricted / Closed)
Artefacts — Conservation:
- Condition (recommended, item scope, Long text)
- Materials (recommended, item scope, List, bound to AAT)
- Dimensions (optional, item scope, Text)
You can see and edit every default field. Deprecated defaults are hidden by default; toggle Show deprecated to see them.
What you can change
For every field:
- Label and help text (cosmetic)
- Required / Recommended / Optional
- Vocab binding — switch the bound vocabulary, or unbind to free-text
- Type — though changing a populated field's type is risky and warns you first
For every category, you can:
- Add new fields in any group
- Deprecate unused fields (hidden but data preserved)
- Apply default vocab bindings to restore the seed bindings if you've drifted
- Reset to defaults for the whole category (offers a backup first)
Org-level vs personal
On Community and Professional, Data Model changes are personal — they affect your account only.
On Team and Enterprise, Data Model is org-wide. Only Admins can edit it. Everyone in the org sees the same schema.
This is intentional: a shared Data Model is critical for consistency in a multi-seat archive.
Migrating an existing Data Model
If you're moving from another catalogue and have an existing schema definition (CSV, JSON, ArchivesSpace template), you can import it via Settings → Exports → Import Profiles → Data Model template. The import shows a diff against your current model — you decide what to merge.
What's next?
- Customising fields — the field-level editor
- Custom fields — how added fields appear in the accession workflow
- Applying domain packs — pre-built schemas for specific domains